Search architecture
January 2024
The ubiquity of search is undeniable, and users have grown accustomed to this paradigm. A noticeable absence of a search capability on your site can impact user experience negatively.
Numerous approaches exist for implementing search on a website, and this article explains one such method from an architectural standpoint. Subsequent articles will guide you through the construction of each component within this architectural design.
With that in mind, let’s get on with it!
Problem
Push content into a search engine. It’s as “simple” as that.
Initial architecture proposal
With that in mind, the following diagram shows a first approach to an extendable architecture:
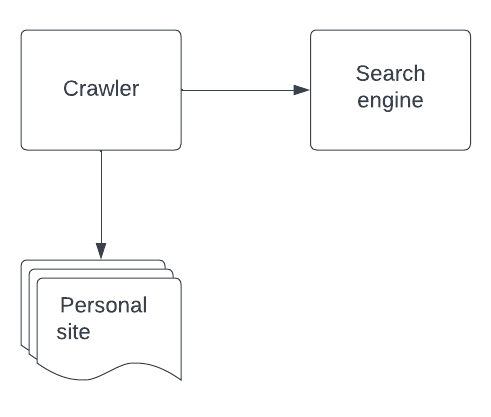
Your content is already there, the new pieces are a crawler and a search engine. The idea is to decouple content creation from indexing. This means that the crawler is responsible of scraping the content on the site, validate it, transform it, and push it to the search engine.
Benefits
This approach allows makes it easy to extend the content to different sites, as well as allowing other consumers of the content (for example AWS Bedrock):
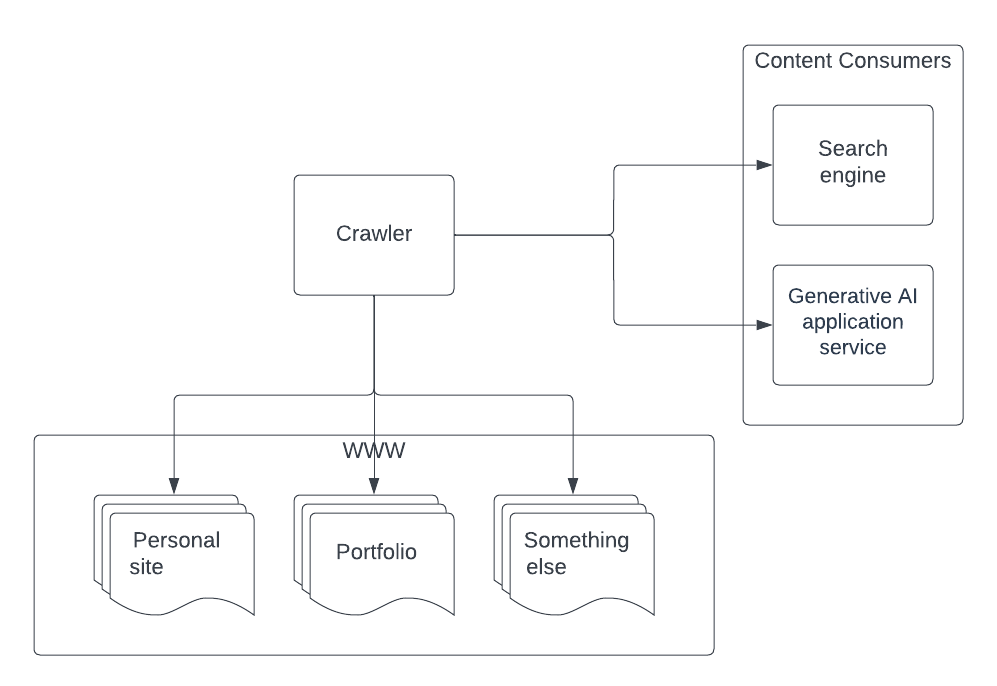
Those two extensions are trivial in this architecture, but they can be difficult when, for example, the content creator has also the responsibility to push to the search index or whatever other consumer is there. The approach might be OK when the content comes only from one site, but it can spire quickly into a maintenance nightmare if there are multiple sites.
That’s all!