Caching strategy for an SSR app integrated with a headless CMS
September 2024
The easiest way to make a site faster is to have a good caching policy, but as the famous words go:
There are only two hard things in Computer Science: cache invalidation and naming things.
This article is going to explore the cache invalidation part of that sentence.
To focus the conversation, it proposes different layers of caching for a service that use a headless content management system (CMS) and a node.js application.
With that in mind, let’s get on with it!
The problem
Your organisation is growing. When you started, you decided to go with a standard CMS platform, like Wordpress or Drupal. It served you well, but content creators have started to complain about it being clunky and that the service is lacking features. Additionally, the original team that maintained the CMS is gone, and the new people don’t like to work with it. In fact, your last developer left because they had to work on that platform.
You’ve made the decision of migrating to a different tech stack, and you are decoupling the content from the presentation. After thinking about it, you choose to have an SSR application that fetches the content from a headless CMS.
You get your proof of concept and things go well. The content creators are happy, they have new features, and a more friendly UX. Your developers are also happy because now they can work faster, in a modern stack, helping them develop themselves. You have improve DevEx and moral is higher.
There is a problem though, performance is not great. You have to think about a caching policy to make your site faster than it was before the migration.
First steps
The first thing is to cache the CMS content. Most headless CMS serve their content from a CDN and they can have different invalidation policies. Some of them use a header for the timestamp of the version you are retrieving, others invalidate the cache on every publication. The former seems like a better idea, and I would recommend looking into this when you choose your headless CMS.
If you go with the one that is based on the timestamp, you need to store the timestamp you’re using somewhere. Your first “cache” will be storing that value. Since it’s not a super important value, you are going to want the latest version often, you should use a simple key value data store like Redis.
This cache is a kind of cache-aside caching. Your server looks first in the cache to fetch the data. If the data is there, it uses it. If the data is not there, it has to fetch the latest data.
In this example, data will be the headless CMS timestamp or version key.
The app is now a bit faster, but the problem is that your content won’t be updated until you invalidate that cache. When using a headless CMS, a good way to invalidate this cache is to configure a webhook when the content is updated in the CMS. When a content creator updates, creates or removes content, get your app to accept the webhook from the headless CMS and update the key for the timestamp in your Redis instance.
Caching on edge
It is likely that your site is still not as fast as it should be. On every request, you are going to build the pages from scratch. You are hitting a CDN to get the content, that’s fine, but you still need to render the page.
To solve that issue, you can start caching on edge with AWS Cloudfront. As a side win, you can also use it to compress your content, adding a layer of optimisation. But this article is about caching.
In AWS Cloudfront you can define the caching policy in any way you want. You can start with expiration dates of one hour, one day, one month. Whatever you want. This makes your site really fast when the you hit the cache.
Your site is now performing as you want, but the issue now is that, if you leave it like that, your content editors will have to wait until the expiration date is reached to see updates to existing content. This is not ideal, that’s why Cloudfront provides ways to invalidate the distribution.
Cloudfront invalidation
Cloudfront provides a way to invalidate the full cache, multiple entries, or just one entry. It does so by invalidating entries based on regular expresions. If you invalidate the distribution with the path /*, it will invalidate all the pages. If you set path to /, it will only invalidate your landing page. This flexibility is exactly what you want.
Coming back to the CMS webhooks, you can follow a similar pattern. When the content is updated in the CMS, the webhook tells your service what content has been updated. Your service then can translate that information into a path. With that path, you can now invalidate the Cloudfront distribution for the updated content.
A possible solution
The final solution might look something like this:
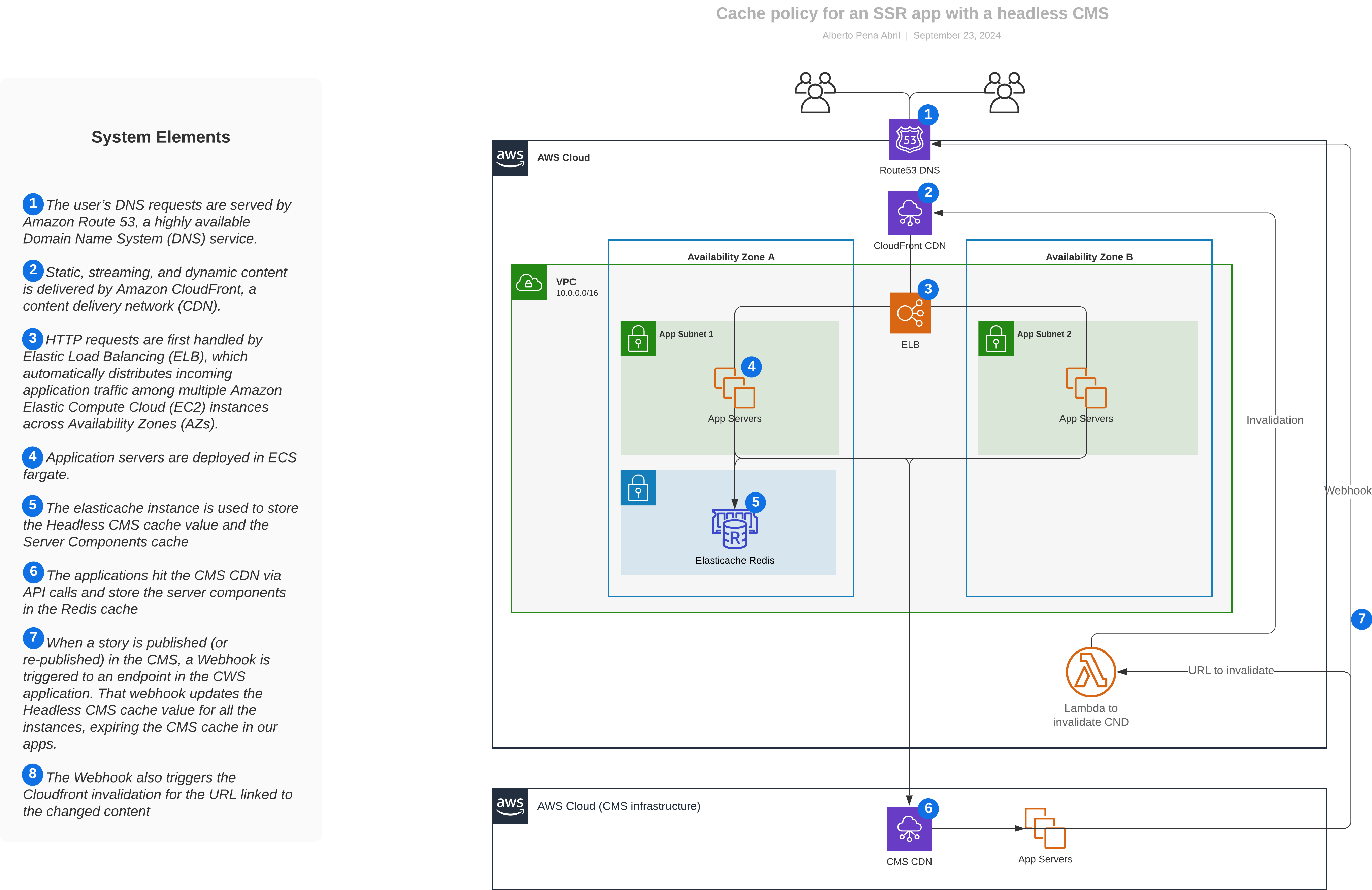
That’s all!